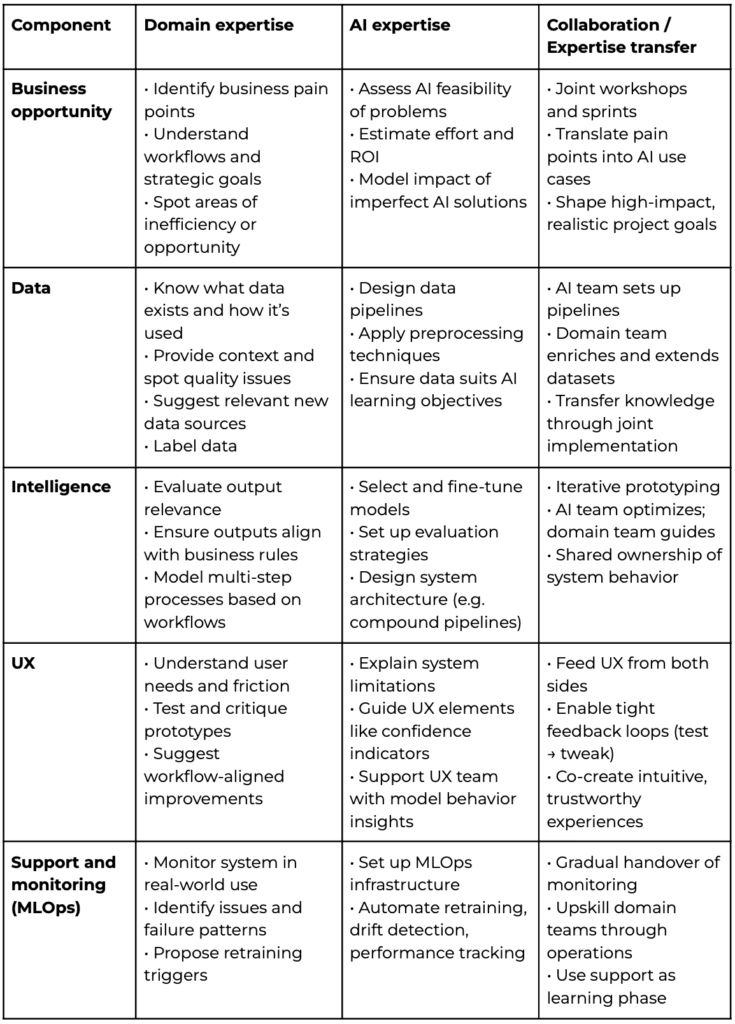

Government Funding Graph RAG
In this article, I present my latest open-source project — Government Funding Graph. The inspiration for this project came from a desire to make better tooling for grant writing, namely to suggest research topics, funding bodies, research institutions, and researchers. I have made Innovate UK grant applications in the past, so I have had an interest in […]
Government Funding Graph RAG Read More »